Study on Enhancing Smart Home Interactions Published in Personal and Ubiquitous Computing

We are excited to announce the publication of our latest research paper in Personal and Ubiquitous Computing. The study, titled "Enhancing smart home interaction through multimodal command disambiguation," and conducted by me and Luigi De Russis, explores an innovative approach to making smart homes more intuitive and responsive to user commands.
Imagine a scenario where a user says, "Set a cozy mood in the living room." This simple command can be interpreted in various ways. Does "cozy" mean dimming the lights, adjusting the temperature, or perhaps playing soft background music? We propose a novel multimodal disambiguation approach that integrates visual and textual cues with natural language commands. We leverage large language models (LLMs) to detect when a user's command is unclear and generate appropriate clarification options. These options are presented to users through either visual representations or textual descriptions, depending on the context and nature of the ambiguity. For instance, if the user asks to "set a relaxing atmosphere," the system might offer visual representations of different room settings, as the concept of "relaxing" is often better conveyed through images. On the other hand, for a command like "adjust the temperature for optimal sleep," the system could provide textual options detailing specific temperature ranges and their benefits for sleep. This adaptive approach ensures that users can clarify their intentions in the most intuitive and efficient manner, enhancing the overall smart home experience.
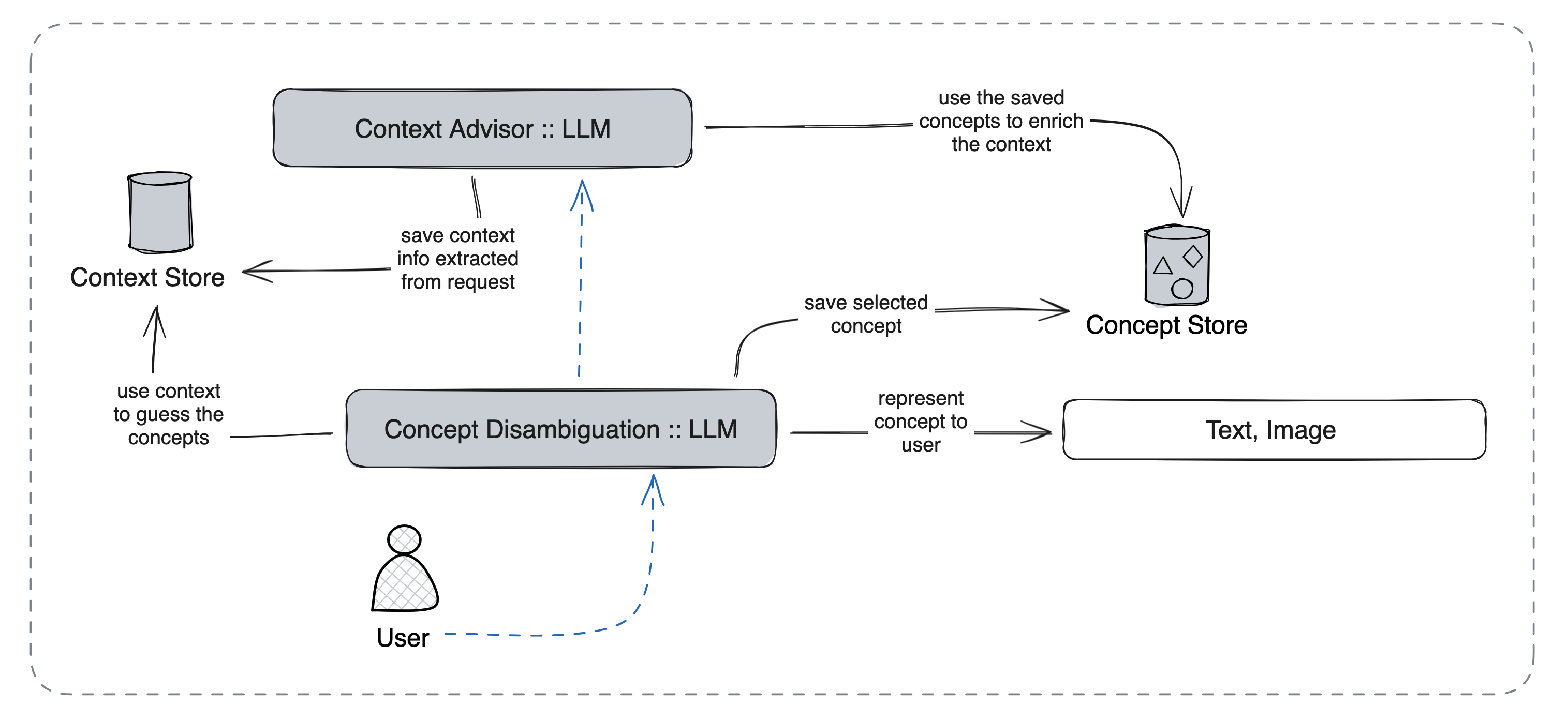
Our method, as illustrated in the image, consists of several interconnected components. The Context Advisor, powered by a Large Language Model (LLM), extracts and saves context information from user requests in the Context Store. This stored context is then used by the Concept Disambiguation component, also driven by an LLM, to interpret and clarify ambiguous user commands. The disambiguation process results in either textual or visual representations presented to the user. Once the user selects their preferred interpretation, this concept is saved in the Concept Store. This stored information is then used to enrich the context for future interactions, creating a feedback loop that continually improves the system's understanding of user preferences and intentions. This cyclical process allows our system to adapt and provide increasingly accurate and personalized responses over time.
The effectiveness of the approach was evaluated through a comprehensive user study involving 13 participants. This study provided valuable insights into how users interact with the system and their preferences for different types of disambiguation. Users generally found the multimodal disambiguation approach helpful in clarifying their intentions and achieving their desired outcomes in the smart home environment. Interestingly, our results showed that textual descriptions were slightly more effective than visual cues for clarification. However, this preference was not universal, and we found that both modalities had their strengths in different contexts.
This work aligns with our broader goal of making technology more accessible and user-friendly, adapting to human communication patterns rather than requiring users to adapt to rigid system commands. The full paper findings, and implications for future research, is now available in the latest issue of Personal and Ubiquitous Computing. We encourage those interested in smart home technology, human-computer interaction, or the application of language models in practical settings to read the complete study.
Additional information: